Spotify의 음악 추천 알고리즘은 어떨까?
딥러닝 기반 음악 추천 프로젝트를 진행하기 전, 교수님께서 건네주신 읽어볼 material 리스트를 읽어보는데 흥미로운 포스트가 있어 정리 겸 공유하고자 한다. 이 글은 먼저 해당 포스트를 참고했음을 밝힌다.
- Key insights of this article
- Music recommendation에서 audio signal을 어떻게 활용할 수 있는지
- audio signal data를 가지고 CNN을 진행할 때 어떤 점을 유의해야하는지
Spotify
![]()
지금은 Youtube Music을 사용하고 있지만, 예전에 잠시 Spotify를 사용한 경험이 있다. 우선 내가 주로 듣는 노래들이 해외 팝송인데, 멜론에서 일반인 DJ들이 만들어놓은 팝송 플레이리스트에는 주로 이미 유명한 메이저 가수들밖에 없었다. 당시 Youtube의 추천알고리즘을 통해 톡톡히 재미를 보고 있었던터라, 한번 음악계의 유투브라고 불리는 Spotify를 쓰고싶었다. 한국에서 spotify 서비스를 이용하기 위해서는 조금 귀찮은 방법을 써야했지만, Spotify는 신세계였다. 내 취향의 노래들이 추천된다는 것이 확실히 느껴졌다. 과연 Spotify는 어떠한 추천시스템을 쓰고 있을까?
이 포스트는 뉴욕 Spotify에서 인턴을 하며 CNN을 활용한 content-based music recommendation 을 작업한 사람이 자신의 접근 방법과 결과에 대해서 얘기한다. 이 포스트의 주된 내용에 대해 여기 정리해보고자 한다.
Spotify’s Recommendation System
Spotify의 기존 추천시스템 - Collaborative Filtering
Spotify는 기존에 collaborative filtering 방법 을 통해 추천했다. collborative filtering 방법은 사용자들의 과거 서비스 아용 데이터를 통해 사용자들의 취향을 알아낸다. 만약 두 사용자가 서로 정말 비슷한 노래들은 듣는다면, 그들의 취향은 비슷할 것이다. 반대로 만약 두 노래가 같은 그룹의 사용자들에게 많이 재생된다면, 그 두 노래는 아마도 비슷할 것이다. 이러한 정보들이 추천에 쓰이는 것이다. Pure collaborative filtering 방법은 추천되는 item에 대한 정보를 이용하지 않는다. 이러한 접근법은 같은 모델이 책을 추천하기도, 영화를 추천하기도 혹은 음악을 추천할 수도 있으므로 다양한 분야에 접목하는 것을 도와준다. 그러나 이는 큰 단점이 될 수 있다.
< CF의 단점 >
* 과거 이용 데이터에 의존하면, 이용 데이터가 많은 인기있는 item들만 주로 추천되므로 다양한 추천이 힘들어진다.
* 비슷한 이용 데이터를 지니지만, 이질적인 content를 지닌 item들이 있어 이용 데이터만 고려하면 잘못된 추천을 할 수 있다.
* 과거 이용 데이터에 의존하므로, 새로운 노래나 비인기 노래들이 추천되지 않는다. 이는 cold-start 문제라고 불린다.
이 단점들을 보완할 수 있는 방법은 content-based recommendation 으로, 추천되는 item, 여기서는 음악에 대한 정보가 활용되는 추천 방법이다. 저자는 특히 음악의 audio signal에 집중했다.
다른 접근 방법 - Content-Based Recommendation
최근 Spotify는 위의 문제들을 완화하기 위해 다른 유형의 정보들을 추천 파이프라인에 추가하는 것에 큰 관심을 가지고 있다. 특히 음악 자체에 추천을 도울 수 있는 다양한 정보들이 있는데, 예를 들면 tag, artist, 앨범 정보, 가사, 노래에 대한 review와 같은 text data, audio signal 등이 있다. 아마 이 중에서는 audio signal이 효과적으로 사용하기에 가장 힘든 데이터일 것이다. audio signal과 사용자의 음악 취향에 영향을 미치는 다른 요소 간에는 semantic gap 이 있다. 물론 audio signal에서 음악의 장르나 어떤 악기를 썼는지, 음악의 무드와 같은 정보들은 추출할 수 있겠지만, artist의 출신 지역과 가사의 테마 같은 정보들은 추출하기 힘들 것이다. 그러나 음악이 어떤 소리를 가지고 있는지 나타내는 audio signal은 사용자가 이 노래를 좋아할 것인지를 유추하는데 분명 큰 역할을 할 것이다.
Audio Signal과 Deep Learning을 활용한 음악 취향 예측
이 포스트의 저자는 바로 audio signal 에 포커스를 두고 동료와 함께 NIPS에 논문 하나를 게재했는데, 그 논문은 Deep content-based music recommendation이다. 이 논문에서 그는 음악의 audio signal로부터 사용자들의 음악 취향을 예측하고자 하였다. Spotify가 기존에 활용한 collborative filtering 모델에서 가져온 음악의 latent representation을 audio signal로 예측되도록 deep learning regression 모델을 학습시켰다. 이 모델을 통해 과거 이용 데이터가 없던 음악들도 collaborative filtering space에서의 representation을 예측할 수 있다.
이 접근 방법의 중요 아이디어는 많은 collborative filtering 모델들이 청취자와 음악을 모두를 a shared low-dimensional latent space에 projecting 하는 식으로 작동된다는 것이다. 이 space에서의 음악의 위치는 음악 취향에 영향을 주는 모든 정보를 담고 있다. 만약 이 space에서 두 노래가 가까이 위치한다면, 두 노래는 아마도 비슷할 것이다. 만약 한 노래가 한 사용자에게 가까이 위치한다면, 사용자가 그 노래를 아직 듣지 않았다는 가정 하에 해당 노래는 그 사용자에 좋은 추천곡이 될 것이다. 즉 저자의 딥러닝 모델을 통해, 과거 이용 데이터에 의존하지 않고, 이 space에서 음악이 어디에 위치할지 예측하여 사용자에게 음악을 추천해줄 수 있다.
About The Deep Learning Model
해당 논문에서 사용된 deep neural network는 2개의 convolutional layer와 2개의 fully connected layer를 가지고 있다. 모델을 train하는 input은 audio의 3초 단위 조각들의 spectrograms로 이루어져있다(spectrograms of 3 second fragments of audio; window of 3 seconds sampled randomly from the audio clips). 그리고 더 긴 audio clip을 가지고 prediction을 할 때는, 긴 audio clip을 3초 windows로 분할한 후에 이 분할된 windows로 부터 얻은 각각의 predictions을 평균내서 사용한다.
여기서 spectrogram이란, 소리를 시각화하여 파악하기 위한 도구로 파형(waveform)과 스펙트럼(spectrum)의 특징이 조합되어 있으며, 시간에 따라 달라지는 한 signal의 주파수들의 spectrum을 시각적으로 볼 수 있다.

저자는 운이 좋게도 Spotify에서 일하면서 큰 사이즈의 음악 데이터와 수많은 collaborative filtering 모델들에서 얻은 다양한 latent factor representations를 사용할 수 있었다. 또한 GPU도 사용할 수 있었어서 논문보다 더 scaling up한 연구를 할 수 있었다고 한다.
1. Architecture - 모델의 구조
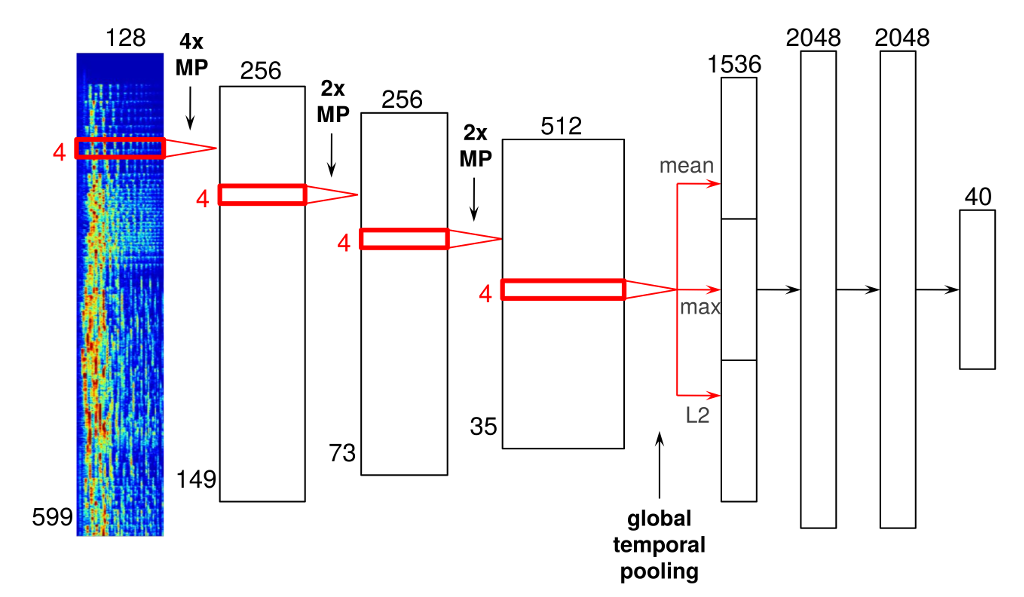
위는 저자가 시도한 모델의 예이다. 4개의 convolutional layers와 3개의 dense layers가 있다. 이 CNN 모델 구조에서 특히 중요한 것은 audio 데이터에 적합하게 설계되었기 때문에, 기존 image data를 다루는 computer vision에서의 CNN과 다른 점들이 있다는 것이다.
(이 부분부터는 영어 원문으로 읽는 것을 추천한다.)
Input
모델의 input은 599 frames와 128 frequency bins로 이루어진 mel-spectrograms 로 이루어져 있다. mel-spectrogram은 딥러닝을 이용하여 음성 인식, 화자 인식, 감정 인식 등에서 많이 쓰이는 음성의 특징 추출 방법이다. 찾아보니 librosa 라이브러리를 활용하면 audio 데이터로 부터 mel-spectrogram을 추출할 수 있다고 한다. mel-spectrogram은 time-frequency representation의 한 양상이다. audio signal 속의 짧으면서 계속 겹쳐지는 windows를 푸리에 변환(Fourier transform)시켜서 얻는다. 푸리에 변환은 frame들로 이루어져 있고, 연속적인 frame들을 하나의 matrix가 되게 합쳐서 spectrogram을 얻는다. 마지막으로 차원을 축소시키기 위해 frequency 축은 기존의 linear scale에서 mel scale로 변환하고, magnitudes는 로그 scale로 변환한다
Convolutional Layer
위 그림에서 빨간색 테두리의 박스가 convolutional layer 이고, input을 따라 쭉 slide 해나간다. 이 convolutional layer의 activation 함수는 ReLU를 활용했다. 특히 여기서 모든 convolution은 1차원이다. convolution은 오직 time 축에서만 진행되고, frequency 축에서는 진행되지 않는다. 물론s spectrogram의 각 두축에서 convolution을 시킬 수 있지만, 저자는 진행하지 않았다. 여기서 중요하게 짚고 가야하는 것은 spectrogram의 가로축과 세로축이 서로 다른 정보를 담고 있다는 것이다. 이는 image data를 다룰 때와 다르다. 그래서 기존에 image data를 다루는 CNN 모델에서 많이 활용되는 정사각형 filter를 쓰는 것은 적절하지 않다.
Max-Pooling Operations
convolutional layer 사이 사이에는 max-pooling operations(MP)가 진행되면서, intermediate representation들을 축소하고 time invariance를 더한다. 총 3번의 max-pooling operations를 진행했는데 첫번째의 filter size는 4 frames이었고, 두번째부터는 2 frames였다.
Global Temporal Pooling Layer
가장 마지막 convolutional layer 뒤에는 global temporal pooling layer 를 사용했다. 이 layer는 전체 시간 축으로 pooling하여, 전체 시간의 학습된 feature들의 값들을 효과적으로 함께 계산해 중요한 특징만을 남긴다. pooling할 때, mean/maximum/L2-norm 3개의 방법으로 pooling한다. 이 방법을 쓸 수 있는 이유는 image data와 다르게 audio signal에서는 feature의 절대적인 위치가 중요하지 않기 때문이다.
이 방법 대신 짧은 audio 조각들을 모델에 학습시키고, output들을 평균내는 식으로 좀더 긴 audio 조각들을 예측하는 식으로도 할 수 있겠지만, 위의 방법이 모델 자체 내에서 핸들링 할 수 있는 방법이기에 더 나은 방법이라고 저자는 말한다.
Fully Connected Layer & Output Layer
이 후에 2048 ReLU를 지닌 fully connected layer 로 연결된다. 모델에서는 이 layer가 2개가 사용되었다. 마지막 layer는 output layer 로, vector_exp 알고리즘(Spotify에서 사용되는 collaborative filtering 알고리즘 중 하나)을 통해 얻은 40 latent factors를 예측한다.
< 기존 image data를 다루는 CNN과 다른 점 >
* input에서 두 축은 다른 정보를 담고 있다. 현재 모델에서 input의 가로는 frequency(주파수), 세로는 frames(혹은 time, 시간)을 나타낸다.
* image data를 다루는 CNN에서 image data의 두 축은 같은 정보를 담고 있다(ex. 각 위치의 픽셀의 RGB 컬러).
* 그래서 저자는 모델 설계시, 모든 convolution을 1차원으로 만들었다. frequency dimension이 아닌 time dimension에서만 convolution이 실행되도록 하기 위해서다.
* 물론 기술적으로 두 축 모두에서 convolution을 실행하는 것이 가능하지만, 저자는 현 모델에서는 그렇게 하지 않았다.
* audio signal에서 특징값들의 절대적인 위치는 사실상 중요하지 않기 때문에, global max pooling이 가능하다.
* image data에서는 특징값들의 위치가 중요하다. 예를 들어, 이미지의 상단 쪽을 보고 구름을 예측할테지만 아래 쪽에서는 양의 하얀 털이 될 수 있다.
2. Training - 모델 학습
모델은 기존 spotify의 collaborative filtering 모델로 얻은 latent factor vectors와 predictions 간의 mean squared error가 최소화되도록 학습되었다. 먼저 latent factor vectors는 unit norm을 가지도록 normalize 되었다. 왜냐하면 음악의 popularity가 지닌 영향을 줄이기 위해서다. 많은 collborative filtering 모델에서 latent factor의 norms는 음악의 popularity와 연관이 있는 것으로 나타났다. 그리고 regularization에 활용된 dense layer에서 dropout이 사용되었다.
3. Variations - 가능한 시도들
1. 더 많은 layer 추가
2. ReLU 대신 다른 activation 함수(ex. maxout units)
3. Max-pooling 대신 stochastic pooling
4. output layer에서 L2 normalization 활용
5. spectrogram을 시간에 따라 늘리거나 압축하는 식의 data augmentation
6. 다른 collborative filtering 모델에서 얻은 다수의 latent factor vectors를 concat하여 사용
모델 분석 - 여기서 Deep Learning Model은 무엇을 학습하는가?
첫번째 convolutional filtering layer의 filters를 시각화하면 아래와 같다.

자세히 보면 각각의 filter들은 4 frames 너비로 굵은 붉은색 세로선으로 구분되어 있다. filter 속 파란색은 양수를, 빨간색은 음수를, 흰색은 0을 나타낸다. 이 시각화를 통해, filter들이 harmonic content(고조파.. 주파수의 성분이라고만 이해했다.)를 담고 있다는 것을 알 수 있다. 그리고 pitch의 높낮이와 사람의 목소리 또한 탐지함을 알 수 있었다고 한다.
여기서부터가 개인적으로 제일 재밌는 지점이다.
lower-level
첫번째 convolutional filtering layer에서는 256개의 filter가 있는데, 저자는 흥미롭게도 각 filter를 maximally activate하는 노래들을 Spotify에서 찾아 각 filter가 어떤 feature를 담아내고 있는지 알려준다. Spotify 가 현재 우리나라에서 서비스되고 있지 않아, 접근할 수 없다고 나오지만 VPN을 활용해서 들어볼 수 있다. 14번, 242번, 250번, 253번 filter를 예시로 보여주는데, 각각의 filter는 vibrato singing/ringing ambience/vocal thirds/bass drum sounds의 feature를 담아낸다는 것을 느낄 수 있었다. 다만 playlists에 담긴 노래들은 장르가 제각각이었는데, 이는 첫번째 convolutional filtering layer의 filters가 low-level 특징을 담아낸다는 것으로 유추할 수 있다. 그리고 본 포스트로 가면 각 filter들의 시각화된 이미지들도 있으므로 비교하면서 확인해볼 수 있다.
저자는 앞선 방법과 달리 노래들에 각 filter들을 시간에 따라 average activation을 한 후, 가장 maximum을 지닌 노래를 찾아 playlists를 만들었다. 즉 이 방법에서 찾은 노래들은 filter가 30초 간격으로 지속적으로 active하다는 것을 의미한다. 이 방법은 좀더 harmonic patterns를 탐지하는데 유용하다. 여기서 예시로 나온 filter들은 특정 pitch와 코드들을 탐지하도록 학습되었다. 청취자의 취향에 특정 pitch나 코드가 영향을 끼치지 않을 것이라고 우리는 생각하지만, 왜 filter들이 이렇게 학습되었을지 저자는 두 가지 가설을 낸다.
- 첫 번째는 모델이 harmonicity를 탐지하도록 학습하기 때문에 filter들이 다양한 종류의 harmonics를 학습한다는 것이다. 그리고 이 filter들은 higher level에서 다양한 pitch 사이 harmonicity를 탐지하도록 pooling된 것이다.
- 모델은 특정 음악 장르에서는 코드와 코드 진행 방법이 더 흔하기 떄문에 이를 학습하는 것이다.
저자는 두 가설 중, 두번째 가설은 모델이 학습하기에 더 어려울 것이므로 첫번째 가설이 적절할 것이라 예상한다.
higher-level
모델 구조에서 점점 더 뒤로 갈 수록, 이전 layer에서 학습된 feature representation에서 higher-level features들이 추출된다. output layer 바로 직 전의 fully-connected layer에서 학습된 filter들은 특정 서브 장르를 선별하여 담고 있는 것으로 나타났다. 그리고 흥미롭게도 몇몇 filter들은 2개 이상의 음악 스타일을 담고 있는 것으로 보였다. 아마도 다른 filter랑 합쳐졌을 때, 차이를 가지는 것으로 보인다. 그리고 특정 filter의 playlist는 중국 노래를 담고 있었는데, 이 filter는 중국 언어를 인식하는 것으로 보였다. 이 외에도 Spanish 랩을 인식하는 듯한 filter가 존재했다.
Similarity-based playlists
모델을 통해 예측된 latent factor vectors를 가지고 비슷한 소리를 지닌 음악들을 찾는데 쓸 수 있다. 저자는 이 방법을 통해 한 노래의 factor vector을 예측하고, 코사인 거리를 활용해 이와 비슷한 factor vectors를 가진 노래들을 묶어 playlist를 만들었다. 즉 여기서 첫번째 track은 하나의 query인 셈이다.
결론
해당 포스트는 2014녀 8월에 작성된 포스트로 이 방법이 지금 현재 2020년의 Spotify에 적용되었는지 궁금했다. 조금의 서칭을 해보니, 지금의 Spotify는 어느정도 노래의 특성을 추천시스템에 활용하고 있는 것으로 보인다! 노래 데이터가 있으면 한번 위에서 설명된 모델 아키텍처로 구현을 해보고 싶다. 그리고 특히 모델링을 떠나서 모델링 결과를 직접 뜯어보고 해석하고 나름의 가설을 세우는 과정이 인상에 남았다. 마무리가 강한 사람이 될 것!
< 추후 참고할 Materials >
- 이 포스트 저자의 http://benanne.github.io/research/
- http://www.slideshare.net/erikbern/music-recommendations-mlconf-2014
- http://erikbern.com/ (저자의 supervisor였던 Erik Bernhardsson의 블로그)
- http://www.slideshare.net/MrChrisJohnson/algorithmic-music-recommendations-at-spotify
- https://towardsdatascience.com/getting-to-know-the-mel-spectrogram-31bca3e2d9d0 (Mel-Spectrogram에 대한 포스트)