Spotify의 플레이리스트에 가장 어울리는 곡들을 어떻게 추천할 수 있을까?
Intro
이 포스트는 2018년 Recosys Challange 주제였던 Spotify Music Recommendation에서 2등을 차지했던 팀의 추천 방법을 다루었습니다. 이 ‘hello world!’팀은 자랑스럽게도 우리나라의 성균관대 팀으로, MMCF(Multimodel Collaborative Filtering)이라는 방법을 고안했는데, MMCF: Multimodal Collaborative Filtering for Automatic Playlist Continuation를 참고하여 공부했습니다.
이 챌린지에서 중요하게 다루어졌던 요소들
추천시스템 분야에서 지속적으로 이슈가 되는 지점들이 있다.
- Popularity bias: popular(i.e. frequently rated) items get a lot of exposure while less popular ones are under-represented in the recommendations.
- Cold-start problem: recommendation system cannot draw any inferences for users or items about which it has not yet gathered sufficient information.
- Context-aware: difficulties in using contextual information to generate context-aware recommendation
위의 이슈들은 음악 추천 분야에서도 그대로 나타난다. 아무래도 사람들과 상호작용이 많은 인기있는 곡들이 데이터가 많기 때문에, 추천을 할 때도 인기있는 곡들 위주로 뽑아진다. 그리고 그렇게 인기있는 곡들만 추천되다보니까 또 인기있는 곡들에 대한 데이터만 쌓이게 되고, 그렇게 악순환이 되는 문제가 Popularity bias 문제이다. 그리고 만약 추천시스템에 새로운 곡이나 새로운 사용자가 들어왔을 때, 추천을 하기 위해 필요한 데이터가 충분치 않아 나타나는 문제가 Cold-start problem이다. 사용자에게 곡을 추천할 때, 사용자의 현재 상황이라던지 기분이나 무드에 맞게 곡이 추천이 되어야하는데 이를 추론할 수 있는 정보들이 있다하더라도 기존 추천시스템에 이 정보를 어떻게 활용할지 어려움을 겪는 것이 Context-aware 문제이다.
2018 Recosys Challange는 이러한 이슈들을 연구자들이 다뤄볼 수 있었던 주제였다. 사용자 맞춤 추천 음악 플랫폼으로 유명한 Spotify가 플랫폼 사용자들이 직접 만든 playlist 데이터를 제공하였으며, Challange의 목표는 각 playlist에 어떤 곡들이 있을지 예측하는 것이었다. 이는 ‘Automatic Playlist Continuation’은 음악 추천시스템의 주요한 태스크라 할 수 있다.
hello world! 팀의 접근
해당 팀은 각 playlist의 기저에 있는 성격 및 특징을 이해하는 것이 중요하다고 밝혔다. 공감이 갔던게, playlist에 들어갈 곡들을 추천하기 위해서는 사용자가 해당 playlist를 어떤 목적으로 만들었는지 이해하는 것이 중요하다. 예를 들어서 어떤 사용자는 한 가수 중심으로 playlist를 만들었을 수도 있고, 혹은 자신이 좋아하는 한 장르를 중심으로 playlist를 만들었을 수도 있다. 또한 기분이나 무드 중심으로 구성된 Playlist들도 음악 플랫폼에서 많이 찾아볼 수 있다. playlist의 성격을 이해하는 것은 음악 추천의 정확성을 높이는 것과 직결되어 있다고 생각한다.
그리고 이 팀은 기존 추천시스템의 이슈 하나하나를 자신들이 고안한 방법과 대응시키면서, 각 이슈들을 어떻게 풀고자 했는지 설명한다. 이를 정리하면 아래와 같다.
In music recommendation context,
- Popularity bias: misinterpret tracks that appear rarely in a playlist
- Cold-start problem: cannot extend user’s playlist that consists of very few tracks
- Context-aware continuation: neglect the context of a playlist as the sequence of tracks or playlist title
The team propose an ensemble of two models,
- autoencoder using both the playlist and its categorical contents to deal with popularity bias and cold-start problem
- character-level convolutional neural network using the playlist title only to deal with context-aware continuation
모델링
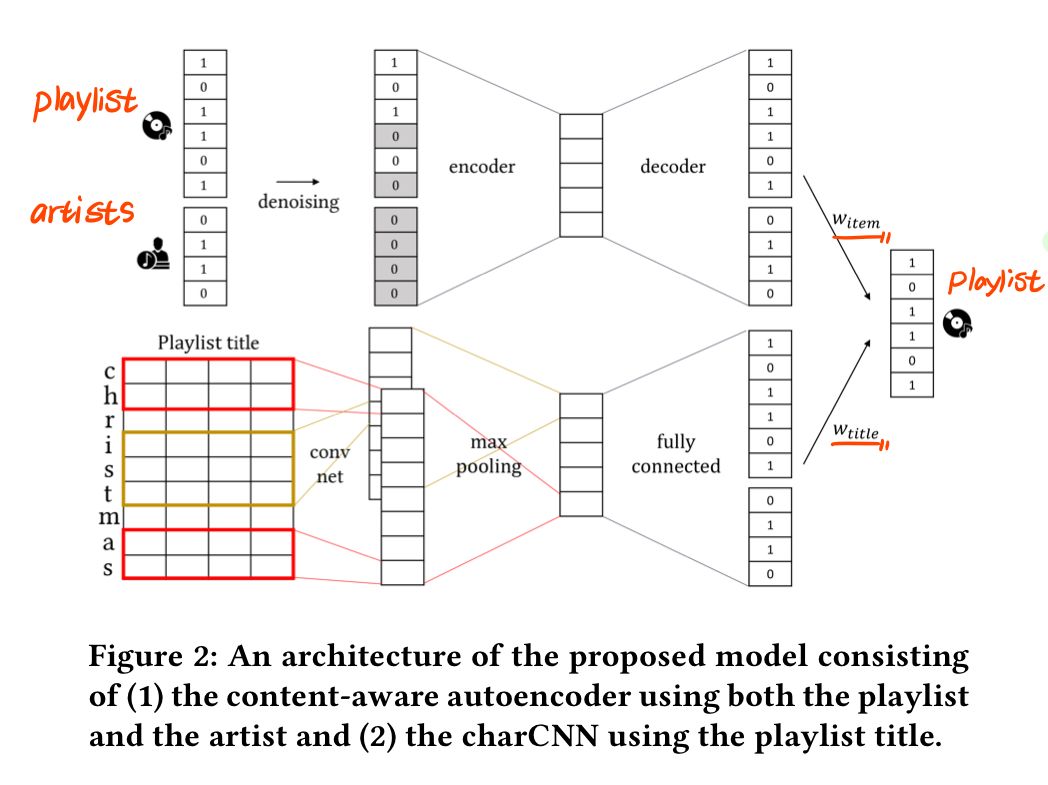
1) autoencoder using both the playlist and its categorical contents(artists)
- content-aware autoencoder
- input: a joint playlist-content vector(playlist p and its content a_p are concatenated)
hide-and-seek approach- randomly select a playlist or its content(artists).
- deactivate its feature vector by setting all values to 0. - either of the playlist or the artist /are fully ignored during training, thereby enforcing that we learn both the marginals and joint information across playlists and contents
- perform a dropout scheme. - For non-zero vector, we randomly choose some values and set them to 0.
- capture the context by considering the order of a playlist. - two dropout strategies(Sequential list = sequential dropout strategy, Shuffled list = random dropout strategy)
- distinguish the observed and missing values for input vectors(one-class collaborative filtering) - uniform weight scheme
2) character-level convolutional neural network using the playlist title only
- charCNN
- learns the latent relationships between playlist and their titles
- playlist titles may contain out-of dictionary words or typos
- character-level embedding
- input: sequence of characters
- output: probabilities for tracks
3) Ensemble
- simple linear combination of two output vectors
- w_item and w_title denote the weights of two models

Preprocessing
- remove samples for tracks and artist that were too rare
- tracks that occur more than 5
- artists who appears more than 3
- Maximum length of a title is set to 25
Experimental Results