변형된 비속어를 잡기 위한 자소 기반 CNN 모델
Intro
현재 Deep Text Lab에서 악성댓글을 탐지하고 문체를 변환하는 프로젝트를 진행 중에 있다. 악성댓글을 탐지하는 단계에서 챌린지가 되는 부분이 2가지가 있는데, 하나는 사용자들이 일부러 비속어를 변형시켜 사용한 형태(변형비속어) 를 잡아내는 것이고, 다른 하나는 비속어가 없는 댓글이지만 문맥적으로 악의가 담긴 댓글 을 탐지하는 것이다. 이번 포스트에 다루는 charCNN은 변형비속어 를 잡아내기 위해 활용했던 모델이다.
프로젝트에서 다루는 온라인 댓글들은 일반적으로 정제된 문장과 다르다. 맞춤법 오류나 오타, 새로운 신조어나 유행어, 특정 커뮤니티에서 쓰이는 혐오 표현들이 가득하다. 또한 유저들은 댓글이 필터링되는 것을 막기 위해, 어떤 단어를 일부러 한글자씩 띄어쓴다거나 자음만 쓴다거나 발음과 유사한 숫자 및 알파벳을 활용하는 경우 등등 다양한 방법으로 댓글을 변형시키기도 한다.
이러한 댓글 데이터에서 비속어 유무 기반으로 악성 댓글 여부를 분류하고자 할 때, 비속어 사전을 사용한 rule-base 모델은 가장 간단하면서도 먼저 변형되지 않은 비속어를 솎아낼 때 효과적이다. 다만 rule-base 모델은 변형된 비속어나 사전에 없었던 새로운 비속어 및 혐오 표현들을 잡지 못한다. 그래서 변형된 비속어를 잡기 위해 다양한 방법들을 고안해보았는데 그 중 성능이 좋았던 모델이 이 charCNN 모델이다. 이 charCNN 모델은 Nexon Developers Conference 2018에서 넥슨코리아 인텔리전스랩스 어뷰징탐지팀에서 발표한 욕설 탐지 방법에서도 사용되었다.
프로젝트에서 이 charCNN을 구현할 때, 참고한 세 가지 논문은 아래와 같다.
- Yoon Kim - Convolutional neural networks for sentence classification: 텍스트 데이터 분류에 CNN을 활용한 최초의 논문(한국인 분!)
- Zhang et al. - Character-level Convolutional Networks for Text Classification: 단어 임베딩이 아닌 알파벳 단위의 input을 CNN에 학습시킨 분류 모델 제안
- 모경현 et al. - 단어와 자소 기반 합성곱 신경망을 이용한 문서 분류: 한국어에 적용하여 자소 단위의 input을 CNN에 학습시킨 분류 모델 제안
이 논문들을 중심으로 내가 공부했던 내용과 구현했던 charCNN 모델, 이 학습된 charCNN 모델을 LIME으로 분석한 과정을 간략히 정리해보고자 한다.
CNN with Text Data
텍스트 데이터에 CNN을 활용한 최초의 시도
Yoon Kim - Convolutional neural networks for sentence classification은 텍스트 데이터에 CNN을 접목시킨 최초의 논문이다.
Character-level CNN
기존의 워드 임베딩에서 벗어나, character 단위의 input을 고안
Zhang et al. - Character-level Convolutional Networks for Text Classification 논문에서는 오직 ‘알파벳’ 단위의 input만을 활용한 CNN을 제안했다.
기존 text classification에서 쓰이는 input은 ‘단어’ 토큰에 기반되어있었다. n-grams과 같이 나열된 단어들의 조합을 사용한 모델이 성능이 좋았기 때문이다. 그러나 단어 토큰에 기반된 word embedding 값을 input으로 쓰는 모델은 텍스트 데이터의 퀄리티(e.g. 오타나 띄어쓰기 오류)나 토크나이저 성능에 영향을 크게 받는다. 그래서 잘 정제되어있는 텍스트 데이터는 모델이 잘 학습할 수 있겠지만, 사람들이 실생활에서 직접 쓰는 글들, 맞춤법오류/오타/줄임말/유행어/이모티콘이 가득한 텍스트 데이터에는 맞지 않는 방법일 수 있다. 반면 charcter-level의 input은 이러한 오류에 강건할 수 있는 힘이 있다.
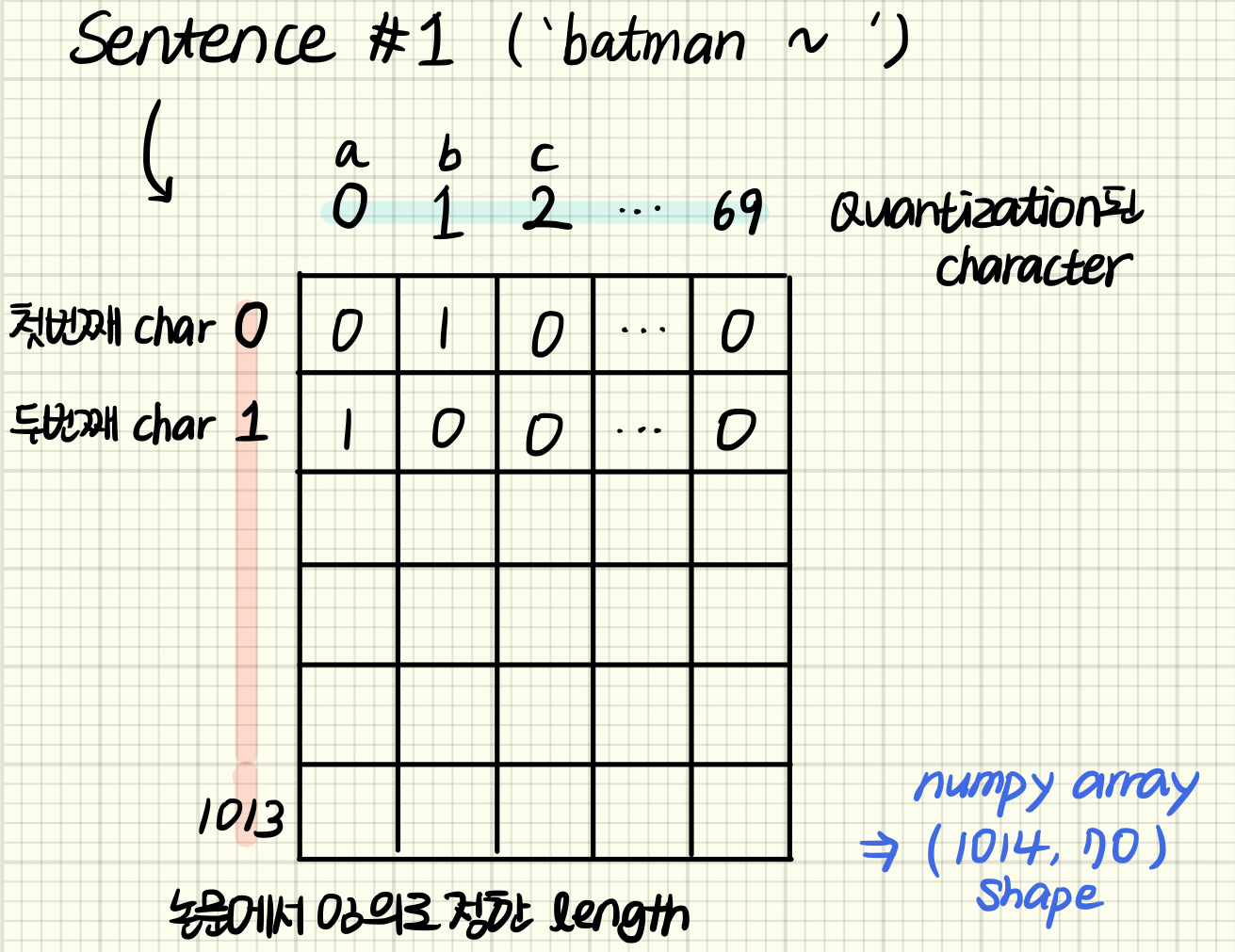
이 논문에서 charcter level의 input을 만들기 위해 quantization이라는, 번역하자면 양자화 과정을 거친다. 양자화 과정은 아주 간단하다. 알파벳 하나하나를 각각 one hot encoding하는 것이다. 알파벳 뿐만 아니라 text data에 존재하는 숫자, 기호까지 one hot encoding 하여 활용할 수 있다. 이 논문에서는 26개의 알파벳, 10개의 숫자, 33개의 기호와 줄바꿈 기호까지 총 70개의 character를 양자화했다. 즉 charCNN 모델에서는 word embedding과 다르게 숫자나 기호도 text classification에 활용할 수 있는 것이다.

양자화 과정을 거친 각 text는 모두 같은 shape으로 맞춰주기 위해 임의로 정한 길이까지 자르거나 모자란 부분은 zero padding하여 아래와 같은 형태가 된다. 예를 들어 두 문장 ‘hello world!’와 ‘Python is the best!’가 있다. 각각 문장의 length는 12, 19이다. 이 둘의 길이를 맞추기 위해 input feature length를 정해야하는데, 만약 가장 긴 문장의 길이인 19에 맞춘다면 첫 문장에 7개의 문자만큼 zero array 패딩 처리해주는 것이다. 이 논문에서는 input feature length를 1014로 잡았는데, 이 길이로 input을 넣었을 때 모델이 충분히 분류해내었다고 한다. 그래서 한 document 당 shape=(1014, 70) 형태를 지니고, input은 최종적으로 shape=(document 개수, 1014, 70)가 된다.
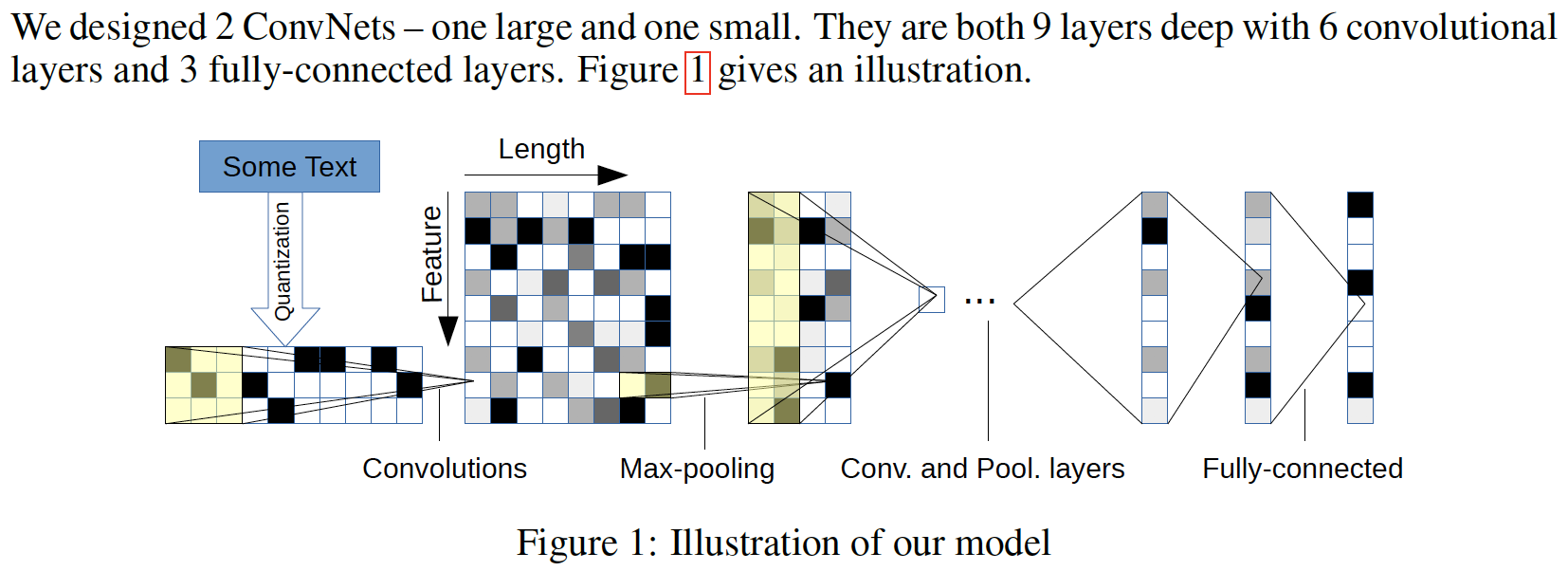
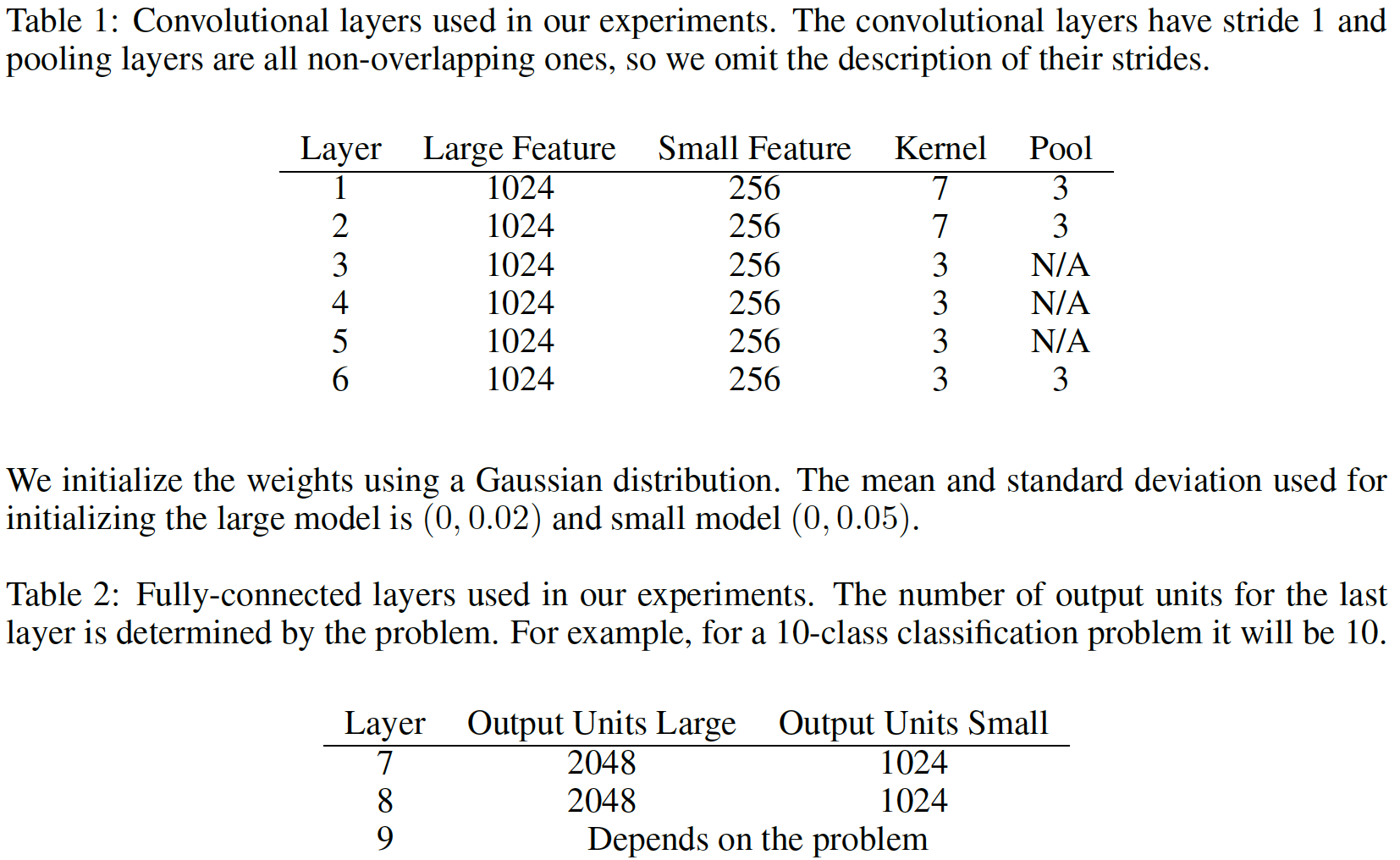
모델은 크게 2가지 Large/Small 모델을 만들었는데 구조는 두개 모두 동일하므로, Small 모델을 기준으로 정리하겠다. 모델은 총 9개의 layer을 쌓았는데, 6개의 Convolutional layer와 3개의 fully-connected layer이다. 또 3개의 fully-connected layer들 사이에 regularization을 위한 2개의 dropout layer(0.5)도 추가하였다. 가중치 초기화는 Gaussian distribution을 사용했으며, 사용한 평균/표준편차는 0/0.05이다. 각각의 layer에 둔 node 수는 아래 표를 참고하자.
한국어 Character-level CNN
character 단위의 input을 활용한 CNN 모델을 한국어에 어떻게 적용할 수 있을까?
위의 영어 text data에서 활용했던 charCNN을 한국어에 적용하기 위해서는 한국어의 특징을 잘 이해하는 것이 필수적이다. 한국어는 영어와 달리 음소 문자이지만 음절 단위로 모아쓰는 특징을 지닌다. 즉, 초성/중성/종성이 모여 한 음절을 이룬다. 그리고 자음만 쓰는 형태로도 의미를 전달할 수 있다. 모경현 et al. - 단어와 자소 기반 합성곱 신경망을 이용한 문서 분류 는 이러한 한국어의 특징을 고민하여 quantization에 잘 녹여내었다. 전반적인 charCNN의 과정, quantization의 기술적인 방법이나 모델 구조는 위의 영어 charCNN과 비슷하다. 하지만 유의깊게 볼 필요성이 있는 부분은 ‘한국어를 어떻게 quantization 했는가’이다.
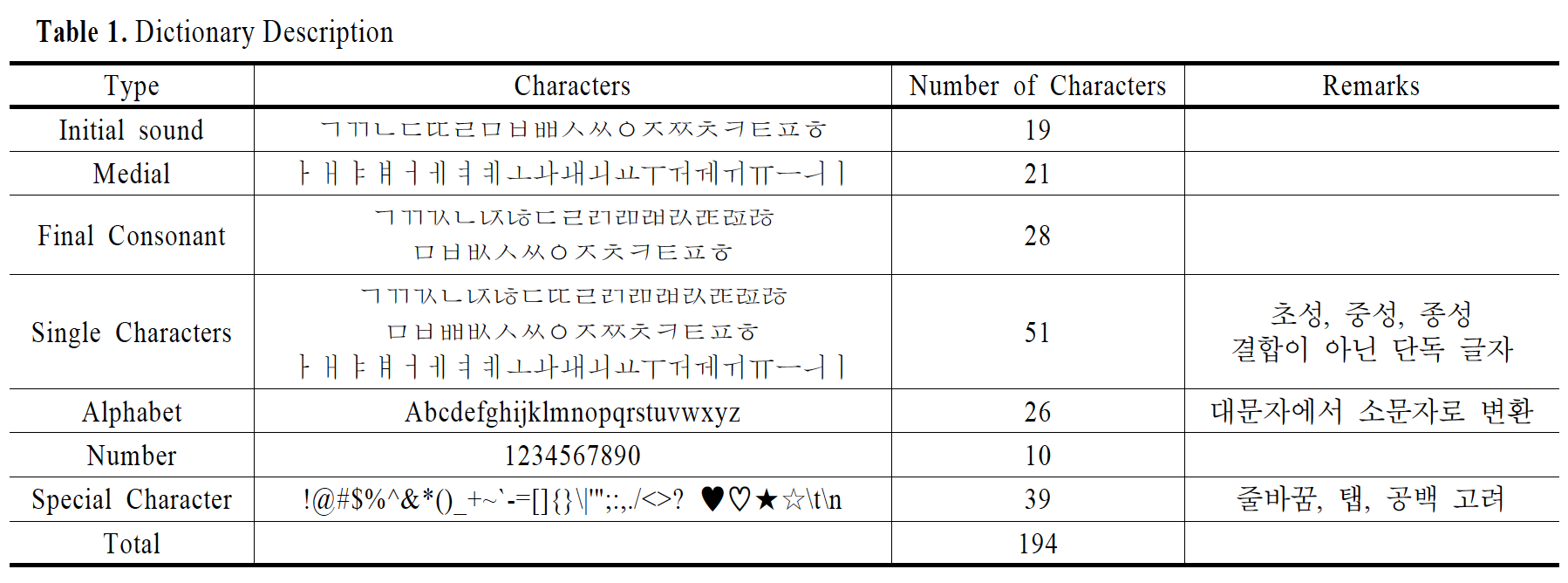
아래의 이미지를 보면, 양자화된 글자는 크게 7가지 종류가 있다. 초성, 중성, 종성, 단독글자, 알파벳, 숫자, 특수기호이다. 우리는 음절 단위 뿐만 아니라 자음 즉, 단독글자(e.g. ㅂㅂ, ㅇㅋ, ㄱㄱ)로도 의미를 전달하기 때문에 단독글자를 따로 양자화하는 것이 중요하다. 그래서 총 194개의 글자를 논문에서 양자화하였다.
또 이전 논문과 다른 점은 character-level의 input 뿐만 아니라, 기존에 사용되던 단어 기반의 word embedding input까지 같이 concatenate하여 모델에 학습시켜보는 실험을 했다는 것이다. 이는 아래의 모델 구조로 확인해볼 수 있다.
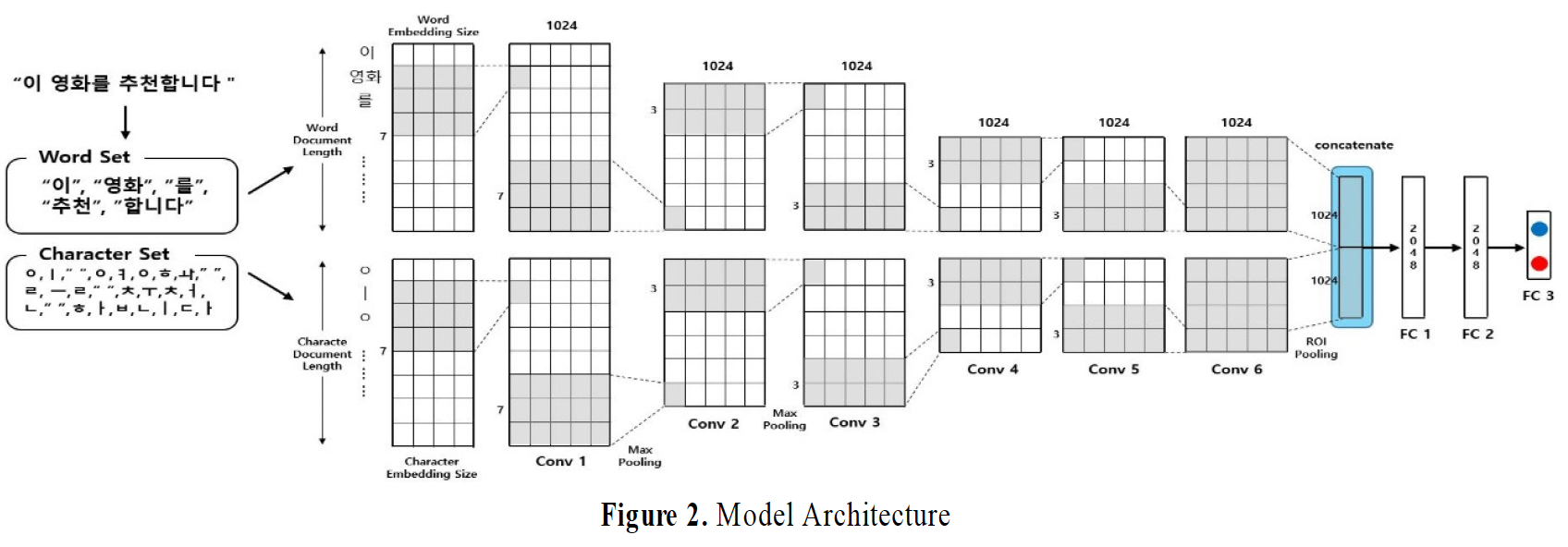
우리 charCNN 모델
온라인 뉴스 댓글 데이터에 charCNN을 적용할 때 생각했었던 것들
우리가 사용하는 데이터는 온라인 뉴스 댓글 데이터이다. 그리고 charCNN의 목표는 악성댓글 여부를 분류하는 것이고, 이를 통해 변형비속어까지 캐치해내고자 하는 것이다. 여기서 우리가 고민했던 포인트들은 아래와 같다.
- Quantization 과정
- 양자화 대상이 되는 문자 정하기
- 뉴스 댓글에는 문자뿐만 아니라 이모티콘도 있고, 멍멍이 이모티콘이나 가지 이모티콘으로 비속어/성적인 표현을 대신하는 사례가 있다.
- 모든 기호를 양자화할 필요가 없다고 생각했다. 악성댓글 여부를 판단할 때 필요한 기호는 사실 몇 개 정해져 있었다. (e.g. ^^ㅣ발)
- 그래서 악성댓글이나 변형비속어를 만드는 데 쓰이는 특수기호, 이모티콘만 양자화 과정에 넣었으며 그 외는 input으로 활용하지 않았다.
- Model Architecture
- 위 논문들이 사용한 각 Layer의 node 수는 그들이 가진 데이터 수에 적합했다.
- 우리는 상대적으로 적은 데이터를 지니고 있기 때문에 node 수나, batch size 를 조절하는 것이 중요했다.
이러한 고민 과정 끝에 만든 charCNN은 이전에 만든 모델보다 비교적 좋은 성능을 가졌다. 모델이 어떻게 각 댓글들의 악성댓글 여부를 판단하는지 이해하기 위해서, 그리고 각 댓글들의 어떤 부분이 그러한 판단을 하는데 중요했는지 알기 위해서 LIME 툴을 사용하여 모델을 들여다보았다.
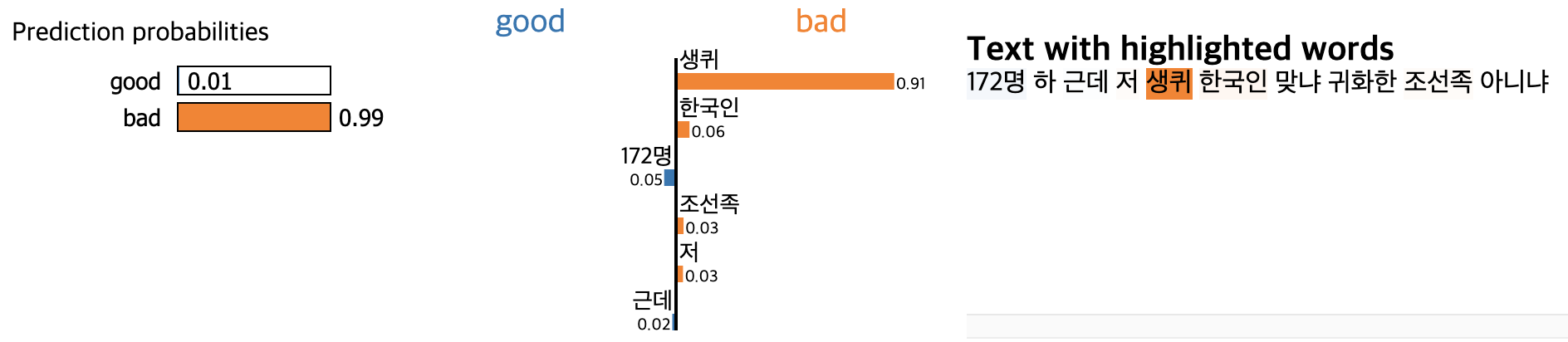
위 이미지를 보면, 새끼라는 비속어를 변형시킨 단어인 생퀴가 분류 시에 중요한 영향을 주었다는 것을 알 수 있다. 변형비속어 외에도 자음만으로 이루어진 비속어들도 잘 잡아내는 양상을 보였다. 하지만 변형비속어 사이사이에 띄어쓰기가 있는 경우는 못잡아내는 경우도 있었다. 그래서 우리는 변형비속어를 케이스별로 나누고, 각 케이스마다 모델 성능이 어떻게 달라지는지를 확인해보려고 한다. 그러면 이 모델을 어떻게 보완할 수 있을지를 알 수 있을 것이다.