추천시스템의 성능을 비교 평가하기 위한 지표인 nDCG
nDCG
- 랭킹기반 추천시스템 에 주로 쓰이는 평가지표
- 관련성이 높은 결과를 상위권에 노출시켰는지 기반으로 만들어야함
- 검색엔진, 영상추천, 음악추천 등의 다양한 추천시스템에서 평가지표로 활용
- CG(cumulative gain)
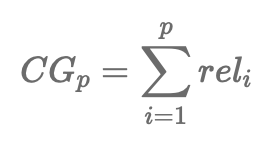
- 상위 p개의 추천 결과들의 관련성(rel, relevance)을 합한 누적값
- rel은 단순히 binary value(관련이 있는지 없는지)이거나 문제에 따라 세분화된 값을 가질 수 있음
- CG는 상위 p개의 추천 결과들을 모두 동일한 비중으로 계산
2. DCG(Discounted Cumulative Gain)
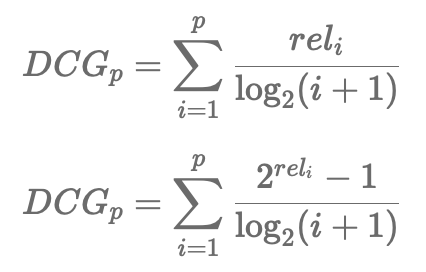
- 기존의 CG에서 랭킹 순서에 따라 점점 비중을 줄여 discounted 된 관련도를 계산하는 방법
- 랭킹 순서에 대한 로그함수를 분모로 두면, 하위권으로 갈수록 rel 대비 작은 DCG 값을 가짐
- 하위권 결과에 패널티를 주는 방식
- 하위권 결과에 패널티를 주는 방식
- 위의 식(1), 식(2)의 두 가지 형태가 모두 쓰임
- 식(1)이 standard한 형태이지만, 랭킹의 순서보다 관련성에 더 비중을 주고싶은 경우에는 식(2)를 사용
- rel이 binary value이면 두 식이 같아짐
- 특정 순위까지는 discount를 하지 않는 방법 등의 다양한 변형식을 사용하기도 함
3. nDCG(normalized Discounted Cumulative Gain)
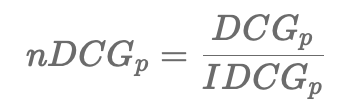
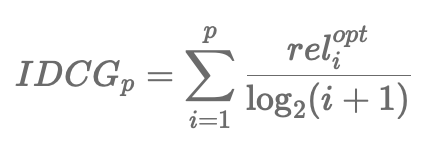
- 기존의 DCG는 랭킹 결과의 길이 p에 따라 값이 많이 변함
- p가 커질수록 누적합인 DCG는 커짐
- p가 커질수록 누적합인 DCG는 커짐
- p에 상관없이 일정 스케일의 값을 가지도록 normalize가 필요함
- IDCG는 (rel가 큰 순서대로 재배열한 후 상위 p개를 선택한 rel_opt)에 대해서 DCG를 계산한 결과
- I for Ideal
- 선택된 p개 결과로 가질 수 있는 가장 큰 DCG 값
- 평가하려는 추천시스템의 DCG가 IDCG와 같으면 nDCG는 1, rel이 모두 0이면 nDCG는 0
- nDCG는 항상 0~1 값으로 normalize
헷갈렸지만, 추천시스템으로 예측한 p개를 relevance 기준으로 나열한 게 아니라 **groud truth에서 relevance 기준으로 나열 후 p개 뽑은 것** 예를 들어, rec_sys_1 = {A, E, C, D, F} → rel은 {3, 1, 2, 2, 1} rec_sys_2 = {A, B, C, G, E} → rel은 {3, 3, 2, 0, 1} 각 item의 관련도: A=3, B=3, C=2, D=2, E=1, F=1, G=0, 나머지=0 ideal gain vector = {**3, 3, 2, 2, 1**, 1, 0, 0, ...} IDCG@5는 5번째까지 잘라서 DCG 구한 것 - nDCG는 항상 0~1 값으로 normalize
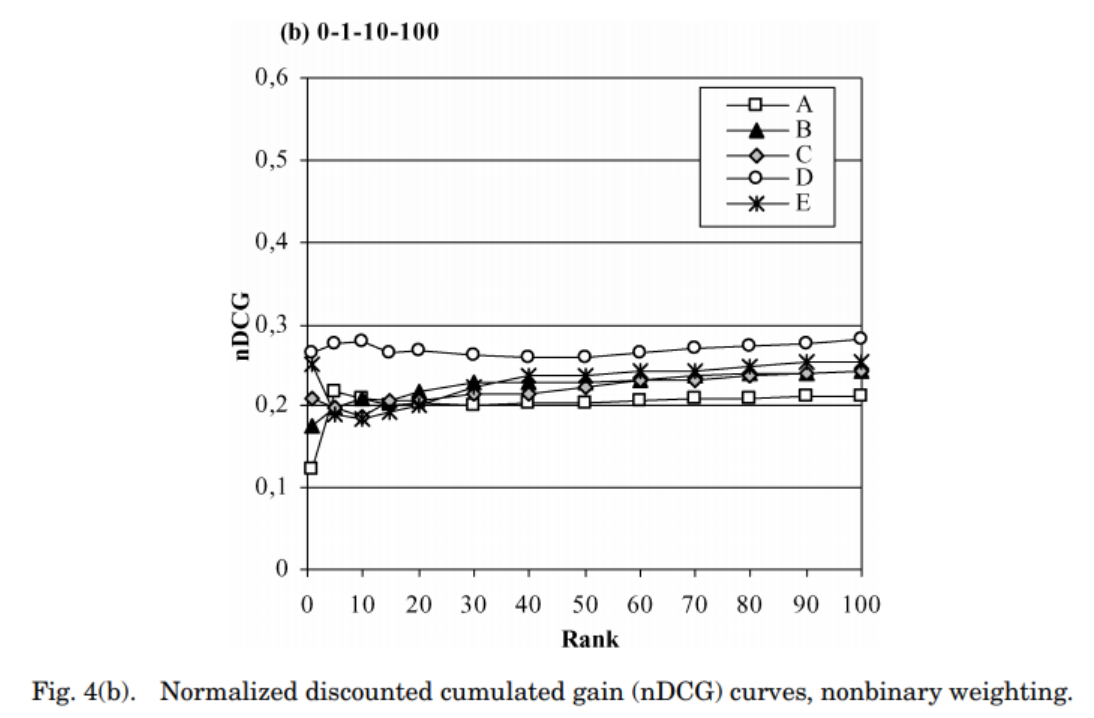
DCG와 nDCG 비교 그래프
-
DCG는 p값이 다르면, DCG 값 자체로 성능의 비교를 할 수 없음
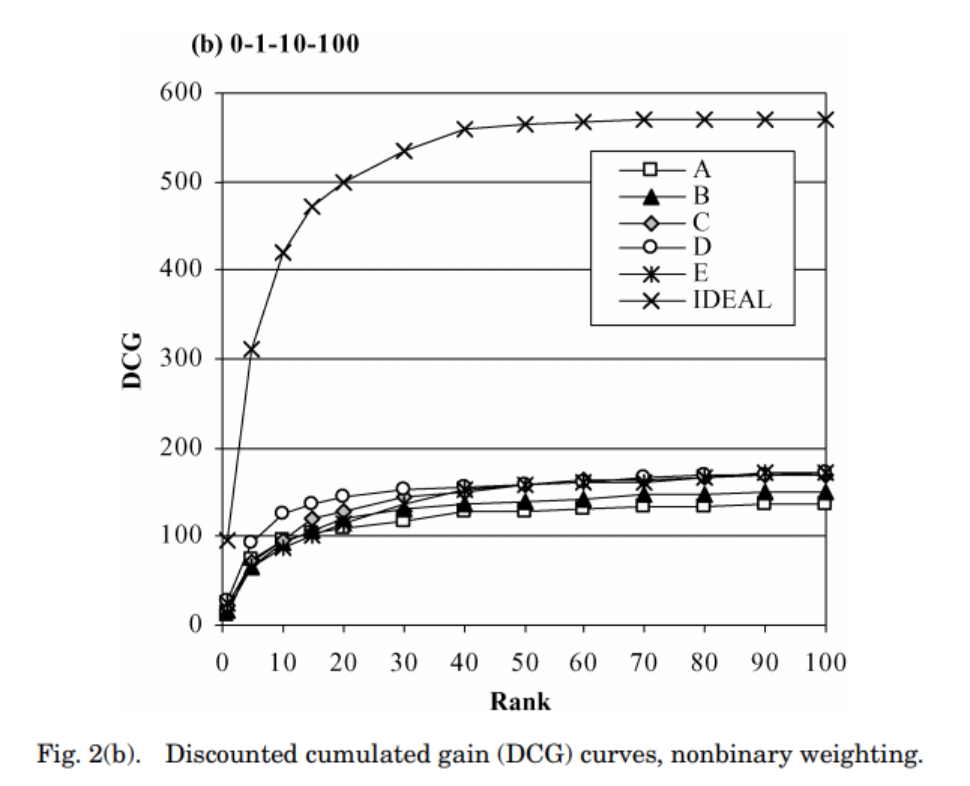
-
nDCG는 p값에 어느정도 독립적이며, 작은 스케일을 갖게됨
nDCG Python
# gt: key는 playlist id, value는 song list인 answer dic
# rec: key는 playlist id, value는 song list인 rec dic
# one_gt는 gt item 하나, one_rec는 rec item 하나
# score는 모든 플레이리스트 nDCG의 평균
# 100개 추천으로, idcg 구할때도 len(gt)이되 len(gt)>100인 경우 len(gt)=100으로 두고 계산
def ndcg(one_gt, one_rec):
dcg = 0.0
if len(one_gt) >= 100:
idcg = sum((1.0/np.log(i+1) for i in range(1, 101)))
else:
idcg = sum((1.0/np.log(i+1) for i in range(1, len(one_gt)+1)))
for i, r in enumerate(one_rec):
if r in one_gt:
dcg += 1.0/np.log(i+2)
return dcg/idcg
## score = 모든 playlist의 ndcg를 평균한 값
score = sum(ndcg(gt[i], rec[i]) for i in rec.keys())/len(rec)